Google a publié en mai 2026 la spécification v0.1 de l’Open Knowledge Format (OKF), un standard ouvert destiné à rendre la connaissance d’une organisation directement exploitable par les agents IA. Contrairement aux catalogues de métadonnées propriétaires qui ont dominé la décennie passée, l’OKF repose sur du Markdown brut, un en-tête YAML et des liens entre fichiers. Aucun SDK, aucun runtime, aucune dépendance cloud.
Cette publication ne ressemble à aucune autre annonce technique récente de Google. Le moteur de recherche ne défend pas ici une plateforme, il pose les bases d’un protocole interopérable, en s’inspirant explicitement du LLM-Wiki pattern théorisé par Andrej Karpathy dans un gist GitHub devenu une référence dans la communauté des développeurs d’agents.
Pour une agence SEO et marketing digital, ce signal est lourd de conséquences. Il acte un glissement que beaucoup pressentaient sans l’admettre, la visibilité dans les résultats de recherche cède progressivement le pas à la visibilité dans les bases de connaissance que consultent les agents.
Pourquoi Google a senti le besoin de standardiser la connaissance
Dans la plupart des organisations, la connaissance utile à un modèle est éparpillée entre des dizaines de surfaces incompatibles. Catalogues de métadonnées avec leurs API propres, wikis internes, commentaires de code, fichiers partagés sur Drive, savoirs tacites des collaborateurs seniors. Quand un agent doit répondre à une question métier précise, il doit reconstruire ce contexte à partir de zéro.
Le diagnostic posé par Google, repris dans l’analyse publiée par le JDN, est sans détour. Chaque équipe qui construit un agent réinvente la même couche d’assemblage de contexte, de manière artisanale, sans interopérabilité. Cette fragmentation a un coût caché. Selon une étude Gartner publiée début 2026, les entreprises engagées dans des projets d’agents IA consacrent en moyenne 38% de leur effort à la préparation et à l’unification des sources de connaissance.
L’équipe de RD Agency observe régulièrement le même schéma chez ses clients TPE et PME. Une fiche produit existe sur le site, une version actualisée dort dans Notion, un tableau Excel sert encore de référence comptable, et le commercial ajoute ses propres notes dans Outlook. Rodrigue Dworaczek constate que cette dispersion devient un blocage opérationnel dès qu’une entreprise veut déployer ne serait-ce qu’un chatbot interne sérieux.
L’OKF propose de remettre tout le monde d’accord avec un format simple, lisible par un humain comme par une machine, versionnable dans Git, hébergeable n’importe où. La promesse est limpide, un bundle rédigé une fois peut être consommé par n’importe quel agent, qu’il s’agisse de Gemini, ChatGPT, Claude ou un agent maison.

Le pari du minimalisme : du Markdown et rien de plus
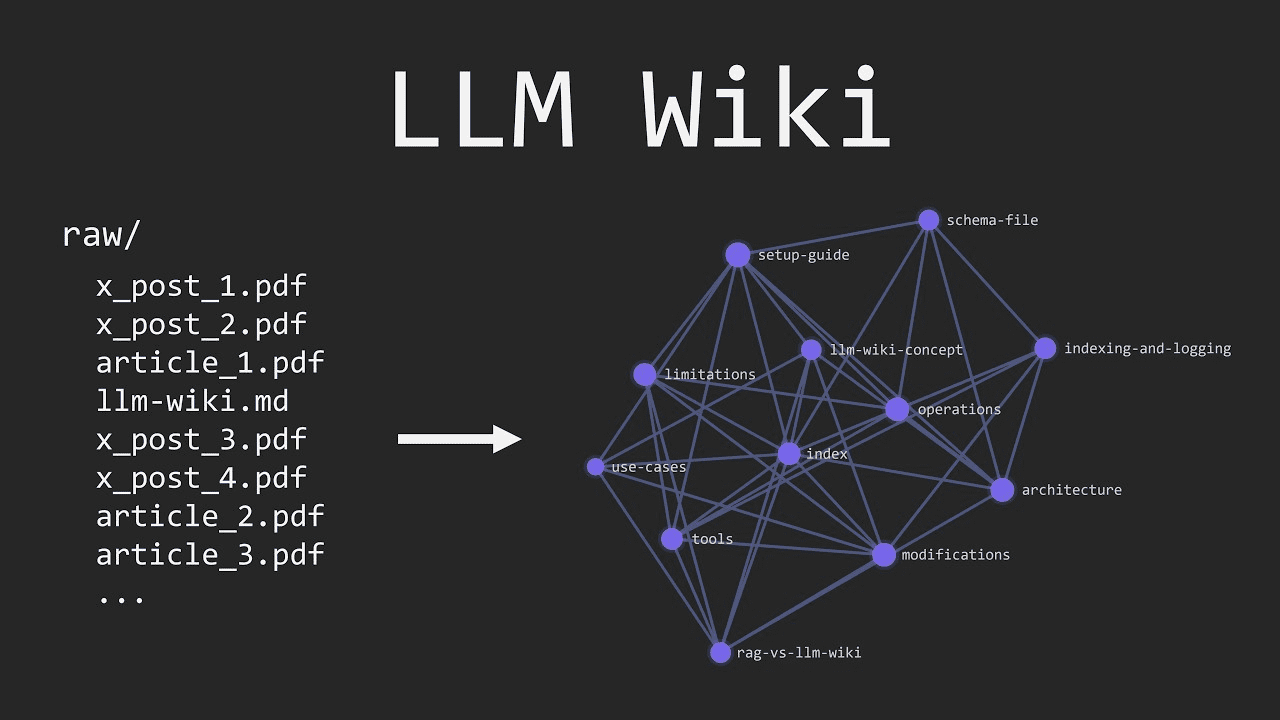
Concrètement, un bundle OKF est un répertoire de fichiers Markdown. Chaque fichier décrit un concept distinct, une table de base de données, une métrique métier, une procédure, un produit, une politique de prix. Le chemin du fichier sert d’identifiant unique du concept dans le système.
Chaque document commence par un bloc YAML restreint à six champs, type, title, description, resource, tags et timestamp. Seul le champ type est obligatoire. Tout le reste, y compris la structure du corps Markdown, est laissé libre. C’est précisément ce qui rend le format adoptable sans formation lourde, contrairement aux schémas Schema.org qui demandent une expertise pointue pour être correctement implémentés.
Les fichiers se référencent les uns les autres via les liens Markdown standards, transformant le répertoire en un véritable graphe sémantique. Cette mécanique simple suffit à reproduire ce que des plateformes propriétaires complexes peinent à offrir, une cartographie navigable des concepts d’une organisation.
Google articule sa conception autour de trois principes assumés. Le minimalisme limite la spécification à une page. L’indépendance entre producteurs et consommateurs garantit qu’un bundle rédigé manuellement par un humain puisse être consommé par un agent automatisé, et inversement. L’indépendance vis-à-vis de toute plateforme assure que l’OKF ne deviendra jamais un produit fermé. La spécification complète est publiée en open source sur GitHub, accompagnée d’un visualisateur HTML statique et de trois bundles d’exemples basés sur des datasets publics BigQuery (GA4 e-commerce, Stack Overflow, Bitcoin).

Le LLM-Wiki pattern formalisé par Andrej Karpathy
L’OKF ne sort pas de nulle part. Le format formalise un pattern qui circulait depuis plusieurs mois dans la communauté des développeurs d’agents, popularisé par Andrej Karpathy dans un gist GitHub très commenté. L’idée centrale tient en une phrase, au lieu d’envoyer les agents chercher les mêmes documents pour les mêmes faits en boucle, on leur donne une bibliothèque Markdown partagée qui s’enrichit au fil du temps.
Karpathy souligne un point qui change tout. Les LLM ne s’ennuient pas, n’oublient pas une référence croisée, et peuvent modifier quinze fichiers en un seul passage. La bureaucratie qui pousse les humains à abandonner leurs wikis personnels est exactement ce pour quoi les modèles excellent. La maintenance d’une base de connaissance devient enfin tenable, parce qu’elle n’est plus humaine.
Ce pattern apparaissait déjà sous diverses formes dans les usages réels. Vaults Obsidian connectés à des agents de code, fichiers de conventions AGENTS.md ou CLAUDE.md à la racine d’un projet, dépôts index.md et log.md consultés systématiquement avant tout travail. Chaque implémentation était jusqu’ici artisanale, propre à une équipe, intransposable telle quelle.
L’apport de l’OKF est précisément cette couche de standardisation. Un wiki construit selon le format peut désormais coopérer avec un autre, qu’il vienne d’une équipe différente, d’une entreprise différente, ou d’un secteur entièrement différent. La connaissance devient transférable, vendable, intégrable, sans intervention manuelle d’un développeur intégrateur.
Du référencement Google à l’exploitation par les agents : le glissement stratégique
La consultante SEO Marie Haynes a formulé l’observation la plus juste sur ce changement de paradigme. Le travail consistant à être trouvé par les moteurs de recherche cède progressivement la place à un travail consistant à rendre la connaissance d’une entreprise exploitable par les agents pour accomplir des tâches concrètes.
La nuance est essentielle. Jusqu’ici, le GEO (Generative Engine Optimization) revenait à optimiser un contenu pour qu’il soit cité par les modèles génératifs dans leurs réponses. Avec l’OKF, la question devient radicalement différente, comment structurer la connaissance d’une organisation pour qu’un agent puisse s’en emparer, naviguer dedans, et agir avec elle.
Cette évolution ouvre aussi une opportunité commerciale nouvelle. Marie Haynes évoque la possibilité de vendre des bundles OKF de connaissance experte. Un cabinet d’avocats, un comptable, un consultant SEO peut désormais commercialiser un bundle décrivant ses processus propriétaires, ses arbres de décision et ses procédures. D’autres organisations pourraient l’intégrer directement dans leur propre système pour rendre cette expertise accessible à leurs agents internes.
Rodrigue Dworaczek note que ce modèle ressemble étrangement à celui des contenus premium vendus aux médias dans les années 2000, mais transposé dans l’économie des agents. La méthodologie Résonance SEO développée chez RD Agency intègre déjà cette logique, penser dès le départ la connaissance produite pour le client comme un actif structuré, et pas seulement comme une suite de pages publiées. Selon une analyse publiée par Google sur son blog produit, plus de 60% des entreprises sondées prévoient d’avoir au moins un agent IA en production d’ici fin 2027.
Ce que ça implique concrètement pour une TPE ou PME
Pour un dirigeant de TPE ou de PME, la première question légitime est de savoir si ce nouveau standard concerne déjà son activité. La réponse est nuancée. À court terme, l’OKF concerne d’abord les organisations qui déploient des agents IA en interne ou qui veulent exposer leur catalogue à des assistants conversationnels publics.
À moyen terme, en revanche, la conséquence est universelle. Toute entreprise qui souhaite être citée, recommandée ou intégrée par un agent IA devra structurer sa connaissance dans un format compatible. Refuser de le faire reviendra à refuser le HTML en 1998.
Plusieurs gestes concrets peuvent être engagés sans attendre. Documenter ses processus métier dans des fichiers Markdown versionnés. Identifier les concepts uniques de son activité (produits, services, méthodologies, zones d’intervention) et leur donner chacun un document dédié. Cartographier les relations entre ces concepts via des liens. Conserver un fichier index.md à la racine pour la navigation.
L’équipe de RD Agency, partenaire France Num, observe que les clients qui avaient déjà investi dans des fiches produits structurées, un glossaire métier et des pages piliers thématiques sont aujourd’hui largement avantagés. Leur travail de migration vers un bundle OKF se résume souvent à reformater de l’existant, pas à reconstruire une base de connaissance. La bonne nouvelle est que l’OKF n’exige aucun outil propriétaire. Un éditeur Markdown, un dépôt Git et un peu de méthode suffisent pour démarrer.
Un mouvement de fond, plus qu’un effet d’annonce
L’OKF v0.1 est explicitement présenté comme un point de départ, pas comme un standard achevé. La spécification tient en une page. Le format évoluera à mesure que producteurs et consommateurs émergeront, et que la communauté apprendra collectivement quelles représentations de la connaissance les agents ont réellement besoin en pratique.
Ce qui est joué, en revanche, c’est la direction. Le SEO traditionnel n’est pas mort, il s’élargit. À côté de l’optimisation pour les moteurs et de la citabilité dans les réponses génératives, une troisième couche apparaît, l’exposition structurée de la connaissance pour les agents. Rodrigue Dworaczek estime que les entreprises qui prendront ce sujet au sérieux dès 2026 disposeront d’une avance structurelle difficile à rattraper.
L’enjeu pour une TPE ou une PME n’est pas de tout convertir demain, mais de commencer à penser sa connaissance comme un actif organisé, versionné et interrogeable. C’est précisément le travail que mène l’équipe de RD Agency aux côtés de ses clients à Paris et au-delà.